ElasticSearch를 이용한 PDF와 Word 문서 검색 서비스 만들기
PDF 문서를 검색하는 방법은 다양하다. Windows의 탐색기를 이용하는 방법에서부터 Google Desktop Search를 이용하는 방법도 있다. 물론 그 외에도 로컬 데스크톱의 문서를 검색해주는 다른 도구를 사용할 수도 있다. 하지만 조직내의 PDF (Word도 가능해요. Tika에서 지원하는 문서를 참고하세요)를 검색해야 하는 방법을 제공해야 한다면 어떻게 해야 할까? 얼마전 누군가가 그런 고민을 하고 있던터라 '그거 그렇게 어렵지 않을텐데요..'라는 생각을 하고선 만들어 봤다. ElasticSearch(이하 ES)에 대해서 잘 알고 계신분께는 큰 도움이 안될 수 있도 있고, 어쩌면 내가 한 방법이 틀릴수도 있다는 사실을 미리 말씀드린다. 구축에 필요한 시간은 서버 설치 포함해서 3시간 정도이다.
ES는 루씬 기반의 검색 엔진이다. 그냥 Json 데이터를 넣어주기만 하면 알아서 인덱싱을 걸어주고 웹 API를 호출하는 것만으로도 구글과 같은 검색 엔진을 구축할 수 있다. 구현할 시스템의 전체적인 구조는 다음과 같다.
1. ES를 활용한 문서 검색 서버
- ES
- 텍스트 추출을 위한 TIKA 라이브러리
- 분석 자동화를 위한 PHP 스크립트
2. 사용자가 입력한 키워드로 문서를 검색할 수 있는 검색 전용 사이트
- Bootstrap을 이용한 사이트 구축
3. 검색에 사용할 문서를 자동으로 등록할 FTP 서버 또는 공유 폴더
- Samba 활용
문서 검색 서버는 다음과 같은 순서대로 작동한다.
1. 문서를 수집하여 특정 폴더에 저장한다.
2. 주기적으로 해당 폴더에 올려진 문서를 분석한다.
2-1. 하나의 문서를 선택한 후 메타데이터(작성자, 생성일, 문서 종류 등)와 본문(텍스트)를 추출한다.
2-2. 이미지로 저장된 PDF 문서의 경우에는 OCR 엔진으로 텍스트를 추출한다.
3. 생성된 JSON 데이터를 ES에 등록한다.
검색 전용 사이트는 다음과 같이 작동한다.
1. 사이트가 로드되면 전체 인덱싱된 문서의 개수를 가져온다.
2. 사용자가 키워드를 입력하면,
2-1. AND 검색인지 OR 검색인지를 판단한다(체크박스 형태로 제공, ES의 기본검색은 OR임)
2-2. "_search?q=" 쿼리를 통해 서버로 전달
2-3. JSON 형태로 결과를 전달 받는다.
3. JSON 데이터를 분석하여 화면에 리스트 형태로 뿌려준다.
ES 설치는 구글神을 통해 쉽게 알 수 있는데, 한글 문서를 분석하기 위해서는 반드시 인덱싱 저장공간을 생성할 때 한글 형태소 분석기를 플러그인으로 등록해야 한다. 이와 관련된 자세한 내용은 다음 링크를 참고하자.
>> ElasticSearch 설치 및 샘플 사용기 (http://mimul.com/pebble/default/2012/02/23/1329988075236.html)
>> ElasticSearch로 로그 검색 시스템 만들기 (http://helloworld.naver.com/helloworld/273788)
>> elasticsearch 설치 및 한글형태소분석기 적용 따라하기 (http://jjeong.tistory.com/711)
또는 이전에 올린 글처럼 자바로된 한글 형태소 분석기를 통해 본문을 형태소 분석한 후 해당 텍스트를 저장하는 방법도 있을것 같다.
>> 형태소 분석기로 웹 문서 파싱하여 단어만 추출해보자 (http://naggingmachine.tistory.com/823)
세상에는 참 福 받아야 하는 사람들이 많다. 소중하게 공유한 자료는 소중하게 공유하는 것으로~
ES 설치는 그렇다고 하더라도 PDF에서 텍스트를 어떻게 추출해야 할까?라는 고민이 될텐데, 사실 처음부터 별다르게 고민하지도 않았다. 어딘가에서 이미 오픈소스로 만들었을테고 이렇게 중요한 라이브러리인 경우에는 보통 Apache 프로젝트로 등록되어 있는 경우가 많으니까. 역시나 찾아보니 있다. tika! 그냥 가져다가 옵션 주고 사용하면 된다. 메타데이터는 XML이나 JSON 형태로 추출이 가능하고 텍스트도 별도로 추출할 수 있다. 이 옵션들을 이용하면 인덱싱에 사용할 데이터를 JSON 으로 구성할 수 있고 만들어진 데이터를 curl을 이용하여 ES에 등록하면 된다.
문서를 분석하기 위해서 사용한 스크립트는 다음과 같다.
이 코드를 살펴보기 위해서는 다음과 같은 디렉터리 구조임을 이해해야 한다.
Search (directory, 루트 디렉터리)
--> elasticsearch (directory)
--> elasticsearch-0.90.7 (directory)
--> create_index.php (file)
--> tika-app-1.4.jar (file)
--> home (directory, 웹 사이트 홈)
--> pdf (directory, 분석할 문서가 있는 디렉터리)
--> download (directory, 분석하고 난 후 다운로드가 가능한 디렉터리)
다음은 create_index.php의 소스 코드이다.
<?php
$dir = "../pdf"; $count = 0; changeDirFileNames($dir); if ($handle = opendir($dir)) { while(false !== ($readdir = readdir($handle))) { if ($readdir != '.' && $readdir != '..' && (strpos($readdir, '.pdf') !== FALSE || strpos($readdir, '.doc') !== FALSE)) { $path = $dir . '/' . $readdir; if (is_file($path)) { process($path); } } } closedir($handle); }
// 디렉터리의 모든 파일 이름에서 열리지 않는 문자를 _로 대체한다. function changeDirFileNames($dir) { $order = array("(", "&", "'", ",", " ", "+" , "@", "-", ")"); if ($handle = opendir($dir)) { while(false !== ($readdir = readdir($handle))) { if ($readdir != '.' && $readdir != '..' && (strpos($readdir, '.pdf') !== FALSE || strpos($readdir, '.doc') !== FALSE)) { $path = $dir . '/' . $readdir; if (is_file($path)) { // 파일 이름 변경 시도 $new_path = str_replace($order, "_", $path); if ($path != $new_path) { exec("mv \"" . $path . "\" \"" . $new_path . "\""); } } } } closedir($handle); } } function process($filename) { ob_start(); passthru("java -jar tika-app-1.4.jar -t ". $filename); $text = ob_get_clean(); $text = trim(preg_replace('/\s+/u', ' ' , $text)); ob_start(); passthru("java -jar tika-app-1.4.jar -j ". $filename); $json = ob_get_clean(); $json_arr = json_decode($json, true); $json_arr['text'] = $text; // 파일 이름을 title로 넣어준다. $order = array(".", "_", "/"); $title = str_replace($order, " ", $filename); $json_arr['title'] = $title; $str = json_encode($json_arr); exec("curl -silent -XPOST 'http://localhost:9200/hr/file/' -d '" . $str . "'"); if (strlen($text) == 0) { echo $filename . " might be image.\n"; } else { echo $filename . " processed\n"; } exec("mv \"" . $filename . "\" ../download"); return ""; }
?>
이 소스 코드를 실행하면 pdf 디렉터리에 있는 문서들을 가져다가 ES에 등록하는데, 인덱스의 이름은 hs 이며, 디렉터리는 file 이고 문서의 아이디는 자동 생성(생략되어 있음)하도록 했다. 만약 문서의 이름에 따라서 업데이트를 하고 싶다면 문서의 이름을 hash 값으로 사용해야한다. 그렇지 않으면 문서가 중복해서 등록된다.
이제 문서의 분석이 준비되었으며, 마지막으로 구글과 같은 검색 인터페이스를 제공하기만 하면 된다.
나의 경우에는 PDF로 작성된 이력서를 검색하기 위한 용도였으므로 다음과 같은 화면을 구성하였다.
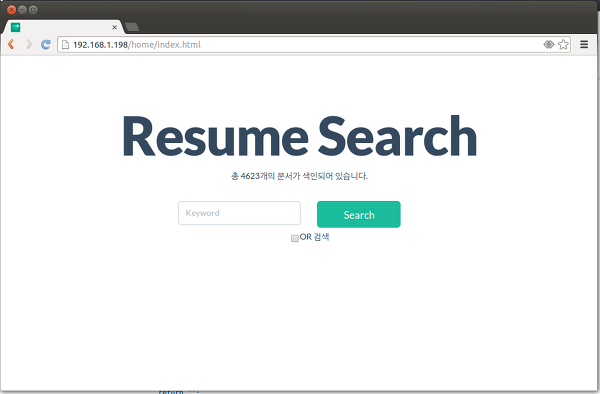
키워드들이 포함된 가능한 많은 문서를 검색해 달라는 요구 사항이 있어서 키워드 양쪽에 *를 추가해서 검색하고 있으며, 페이징 기능을 추가하지 않았다(가져오는 갯수는 10000으로 설정). 원한다면 얼마든지 코드를 편집할 수 있을 것이다.
다음은 index.html 파일의 소스 코드이다.
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <title>PDF Search System</title> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <!-- Loading Bootstrap --> <link href="css/bootstrap.css" rel="stylesheet"> <!-- Loading Flat UI --> <link href="css/flat-ui.css" rel="stylesheet"> <link rel="shortcut icon" href="images/favicon.ico"> <!-- HTML5 shim, for IE6-8 support of HTML5 elements. All other JS at the end of file. --> <!--[if lt IE 9]> <script src="js/html5shiv.js"></script> <![endif]--> </head> <body> <div class="container"> <div class="demo-headline"> <h1 class="demo-logo"> Resume Search </h1> <div id="count_index"></div> <br><br> <div class="span3"></div> <div class="span3"> <input type="text" class="login-field" value="" placeholder="Keyword" id="search-keyword" /> </div> <div class="span2"> <a class="btn btn-primary btn-large btn-block" href="#" id="search-button">Search</a> </div> <br><br><br> <div class="span12"><input type="checkbox" name="chk_operator" id="chk_operator" value="OR 검색">OR 검색 <br><br> <div id="count_result"></div> </div> <!-- /demo-headline --> <div class="span12"> <div class="block"> <div id="result_table"> </div> </div> </div> <!-- Load JS here for greater good =============================--> <script src="js/jquery-1.8.2.min.js"></script> <script src="js/jquery-ui-1.10.0.custom.min.js"></script> <script src="js/jquery.dropkick-1.0.0.js"></script> <script src="js/custom_checkbox_and_radio.js"></script> <script src="js/custom_radio.js"></script> <script src="js/jquery.tagsinput.js"></script> <script src="js/bootstrap-tooltip.js"></script> <script src="js/jquery.placeholder.js"></script> <script src="http://vjs.zencdn.net/c/video.js"></script> <script src="js/application.js"></script> <!--[if lt IE 8]> <script src="js/icon-font-ie7.js"></script> <script src="js/icon-font-ie7-24.js"></script> <![endif]--> <script type="text/javascript"> var gaJsHost = (("https:" == document.location.protocol) ? "https://ssl." : "http://www."); document.write(unescape("%3Cscript src='" + gaJsHost + "google-analytics.com/ga.js' type='text/javascript'%3E%3C/script%3E")); </script> <script type="text/javascript"> try{ var pageTracker = _gat._getTracker("UA-19972760-2"); pageTracker._trackPageview(); } catch(err) {} $("#search-button").click(function() { search(); }); $("#search-keyword").live('keypress', function(e) { if (e.which == 13) { search(); } }); $(document).ready( function() { update_count(); }); // count 업데이트 function update_count() { $.ajax( { url: 'http://192.168.1.198:9200/hr/file/_count', dataType:'json', type: 'get' }).done(function(data) { if (data != null) { html = "총 " + data.count + "개의 문서가 색인되어 있습니다."; $("#count_index").html(html); } }).error(function(e) { alert("error"); }); } // 검색 메뉴 실행 function search() { var keyword = $("#search-keyword").val(); if (keyword.length == 0) { alert('입력된 키워드가 없습니다.'); return; } var start = new Date().getTime(); var checked = "&default_operator=AND"; if ($("#chk_operator").is(':checked')) { checked = "&default_operator=OR"; } $.ajax( { url: 'http://192.168.1.198:9200/hr/file/_search?size=10000&q=*' + keyword + '*' + checked, dataType:'json', type: 'get' }).done(function(data) { if (data != null) { var count = 0; var html = "<table class='table table-striped'><thead><th width=30>순서</th><th>파일이름</th><th width=50>구분</th><th width=150>생성시간</th></thead>"; var end = new Date().getTime(); var time = end - start; html_count = "총 <b>" + data.hits.hits.length + "</b>개의 문서가 검색되었습니다.<br>" + (time/1000) + "초의 시간이 소요되었습니다."; $("#count_result").html(html_count); $.each(data.hits.hits, function(index, value) { count++; var docu_type = "문서"; if (value["_source"]["text"] == "") { docu_type = "이미지"; } html += "<tr><td>" + count + "</td><td>" + "<a href='../download/" + value["_source"]["resourceName"] + "' target=_blank>" + value["_source"]["resourceName"] + "</a></td><td>" + docu_type + "</td><td>" + value["_source"]["created"] + "</td></tr>"; }); html += "</table>"; $("#result_table").html(html); } }).error(function(e) { alert("error"); }); } </script> </body> </html>